
Desde hace algunos años se han ido produciendo grandes avances tanto en hardware como en software que están posibilitando la construcción y uso de sistemas inteligentes, incorporándose poco a poco en nuestro día a día.
En este post vamos a ver uno de los campos de la Inteligencia Artificial que más está evolucionando actualmente en el desarrollo móvil, Machine Learning, y cómo podemos implementarlo en nuestras aplicaciones iOS mediante el framework nativo Core ML.
¿Qué es Machine Learning?
A grandes rasgos, podríamos definir Machine Learning como uno de los campos de la Inteligencia Artificial en el cual un sistema es capaz de aprender automáticamente, pudiendo así tomar decisiones de forma autónoma sin la intervención ni supervisión de un humano.
Este proceso de aprendizaje se lleva a cabo mediante algoritmo complejos, los cuales pueden clasificarse en función de sus características y la forma en la que están implementados. Algunos de los algoritmos más importantes son:
- Algoritmos de regresión
- Algoritmos de agrupación
- Algoritmos bayesianos
- Árboles de decisión
- Redes neuronales
- Aprendizaje profundo
- SVM (Support Vector Machine)
Estos algoritmos permiten detectar patrones de comportamiento a raíz de unos datos de entrada y generar unas respuestas/decisiones en base a estos. La razón por la que existen diversos tipos de algoritmos es porque unos están más enfocados a realizar cierto tipo de detecciones (son más eficientes a la hora de procesar cierto tipo de datos).
Una vez detectados estos patrones, el sistema puede predecir qué respuestas debe tomar para un nuevo conjunto de datos de entrada, basándose en aquellos patrones que ya conocía previamente. Si detecta nuevos patrones, el sistema se retroalimenta y pasa a incorporar este conocimiento a su base de patrones conocidos, perfeccionando así la toma de decisiones.
En el ejemplo que veremos más adelante utilizaremos un modelo que utiliza un algoritmo de red neuronal.
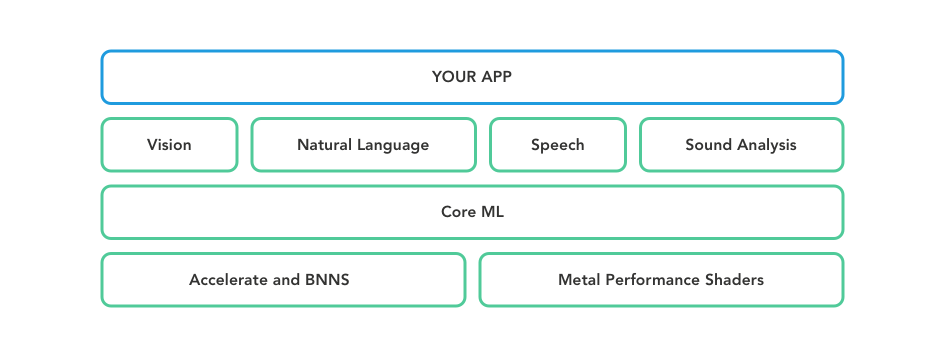
Core ML
Core ML es un framework nativo desarrollado por Apple que permite integrar y utilizar modelos de Machine Learning en nuestras apps.
Un modelo es el resultado de aplicar un algoritmo de Machine Learning a un conjunto de datos. Gracias a estos datos, como hemos dicho anteriormente, nuestro modelo podrá realizar predicciones basadas en nuevos datos de entrada.
La primera versión de Core ML se desarrolló para iOS 11, aunque en cada nueva versión de iOS se han ido introduciendo nuevas funcionalidades y mejoras.
Podemos utilizar tanto modelos propios como modelos open source ya entrenados. Para crear nuestros propios modelos, Apple nos proporciona la herramienta Create ML, que ya viene incluida dentro del Kit de desarrollo de Xcode.
También disponemos de una herramienta para convertir modelos open source en otros formatos (Tensorflow, Keras, Caffe, etc.) al formato de modelo que utiliza Core ML. Este conjunto de herramientas son llamadas coremltools.
Por otra parte, los modelos de Core ML permiten la predicción de:
- Imágenes. Identifica qué tipo de objeto aparece en una imagen: un tipo de animal concreto, una planta, una persona, un rostro, etc.
- Sonidos. Identifica diferentes tipos de sonido: es capaz de predecir qué instrumento está sonando, el ladrido de un perro, el llanto de un bebé, etc.
- Análisis de textos. Identifica partes de un texto, tipos de palabras (adjetivos, verbos), lugares, nombres de persona, organizaciones, etc.
- Conversión de audio a texto (text to speech). Esto podemos verlo claramente en el asistente virtual Siri, que transforma lenguaje hablado en texto para posteriormente analizarlo e interpretarlo.
Ejemplo: Clasificador de imágenes
A continuación veremos la implementación de un ejemplo en el que podremos predecir en tiempo real qué tipo de objeto estamos viendo a través de la cámara del dispositivo.
Para ello nos apoyaremos en Vision, otro framework nativo de Apple para computerización y procesamiento de imágenes. Este framework ajustará el tamaño y formato de las imágenes para que puedan ser utilizadas por nuestro modelo para la predicción posterior. Ambos frameworks, Vision y Core ML, se integran y funcionan conjuntamente de forma transparente para el programador.
Para realizar las predicciones utilizaremos un modelo pre-entrenado llamado MobileNet. Podemos descargarlo desde aquí.
1. Previsualización de la cámara
Lo primero que haremos será implementar la previsualización de la cámara. Para ello, debemos implementar un método para pedir al sistema el acceso a la cámara.
private func requestCameraPermission(completionBlock: @escaping CompletionBlock,
failedBlock: @escaping FailedBlock) {
let status = AVCaptureDevice.authorizationStatus(for: .video)
switch status {
case .authorized:
completionBlock()
case .denied, .restricted:
failedBlock(.cameraPermissionDenied)
case .notDetermined:
AVCaptureDevice.requestAccess(for: .video) { granted in
if granted {
completionBlock()
} else {
failedBlock(.cameraPermissionDenied)
}
}
@unknown default:
fatalError("Need to handle new status: (status)")
}
}
Incluiremos en el Info.plist del proyecto los permisos de cámara NSCameraUsageDescription.
Una vez el usuario nos ha dado permisos de cámara, tendremos que mostrar la previsualización utilizando las clases AVCaptureSession y AVCaptureVideoPreviewLayer.
Crearemos un método para configurar nuestro objeto session:
- Iniciamos la configuración de nuestra sesión. Para este ejemplo, nos basta una resolución de 640x480px. De hecho, es mejor utilizar una resolución relativamente baja para que las predicciones de Core ML sean más rápidas.
- Añadimos el input de la cámara a nuestra sesión.
- Añadimos el output
videoDataOutputpara poder capturar los frames que estamos obteniendo de la cámara del dispositivo. Estos frames son los que analizaremos con Core ML para realizar las predicciones (lo veremos más adelante). Establecemos atrueel atributoalwaysDiscardsLateVideoFrameya que no nos interesan los frames que se vayan generando mientras estemos procesando una predicción. - Finalizamos la configuración y arrancamos la sesión.
private func startCaptureSession() throws {
guard let device = AVCaptureDevice.default(for: .video),
let input = try? AVCaptureDeviceInput(device: device) else {
throw CameraError.videoCaptureNotFound
}
// 1
session.beginConfiguration()
session.sessionPreset = .vga640x480
// 2
if session.canAddInput(input) {
session.addInput(input)
}
// 3
if session.canAddOutput(videoDataOutput) {
videoDataOutput.alwaysDiscardsLateVideoFrames = true
videoDataOutput.setSampleBufferDelegate(self, queue: videoDataQueue)
session.addOutput(videoDataOutput)
}
// 4
session.commitConfiguration()
session.startRunning()
}
Una vez tenemos nuestra sesión configurada, es hora de mostrar por pantalla la previsualización.
- El método
showCameroPreview()se apoya enstartCaptureSession()para configurar la sesión, como hemos visto anteriormente. - Si la sesión se configuró correctamente, procedemos a crear nuestra preview utilizando la clase
AVCaptureVideoPreviewLayer. Establecemos su frame, que coincidirá con las dimensiones de la vista de nuestro ViewController, y además utilizaremos.resizeAspectFillcomovideoGravitypara que la preview ocupe todo el layer. Finalmente, insertamos nuestro layer en la vista.
private func showCameraPreview() {
do {
// 1
try startCaptureSession()
// 2
cameraPreviewLayer = AVCaptureVideoPreviewLayer(session: session)
cameraPreviewLayer?.frame = view.bounds
cameraPreviewLayer?.videoGravity = .resizeAspectFill
if let layer = cameraPreviewLayer {
view.layer.insertSublayer(layer, at: 0)
}
} catch {
guard let cameraError = error as? CameraError else { fatalError("Need to handle unexpected error: (error)") }
showError(cameraError)
}
}
Y con esto ya tendríamos la visualización de la cámara.
2. Captura de los frames de vídeo
El siguiente paso es capturar los frames de vídeo. Necesitaremos un objeto de tipo AVCaptureVideoDataOutput, una cola donde se procesarán y se nos devolverán los frames de vídeo y, por último, implementar el protocolo AVCaptureVIdeoDataOutputSampleBufferDelegate.
private let videoDataOutput = AVCaptureVideoDataOutput() private let videoDataQueue = DispatchQueue(label: "VideoDataQueue", qos: .userInteractive)
Definimos la cola con un qos (Quality of Service) de tipo .userInteractive para que el sistema aplique mucha prioridad a esta cola y se ejecute de forma frecuente, ya que la detección de objetos se hará en tiempo real y nos interesa que sea rápida.
Procedemos ahora a implementar el protocolo:
- Convertimos el pixelBuffer, que es una representación raw del frame de vídeo, en un CIImage.
- Obtenemos la orientación del dispositivo, ya que necesitamos saber la orientación de la imagen. Dependiendo de la orientación del dispositivo, la imagen tendrá un tipo de orientación u otra.
- Procedemos a procesar la imagen para realizar la predicción.
// MARK: - AVCaptureVideoDataOutputSampleBufferDelegate
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// 1
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return }
let image = CIImage(cvImageBuffer: pixelBuffer)
// 2
let exifOrientation = UIDevice.current.exifOrientation()
// 3
classify(image: image, orientation: exifOrientation)
}
}
Ya tenemos los frames de vídeo. Sólo nos queda el último paso, el más importante: procesar los frames y predecir lo que estamos viendo a través de la cámara.
Aquí es donde entran en juego los frameworks Vision y Core ML.
3. Procesamiento de imagen y predicción con Core ML
Para realizar predicciones con Core ML vamos a necesitar estas 3 clases:
- VNCoreMLModel. Encapsula un modelo de Core ML.
- VNImageRequestHandler. Encapsula la imagen que se va a utilizar para realizar el procesamiento y posterior predicción.
- VNCoreMLRequest. Ejecuta el modelo de Core ML con el que se instancia el objeto y realiza la predicción de la imagen que le pasemos. Finalmente devuelve dicha predicción como resultado.
Veamos primero cómo creamos el handler de la clase VNImageRequestHandler:
- Creamos el handler con la imagen y su orientación.
- Procesamos la imagen a través del objeto classificationRequest.
private func classify(image: CIImage, orientation: CGImagePropertyOrientation) {
// 1
let handler = VNImageRequestHandler(ciImage: image, orientation: orientation)
do {
// 2
try handler.perform(
El objeto classificationRequest es de tipo VNCoreMLRequest y, como dijimos, se encarga de ejecutar el modelo de Machine Learning para realizar la predicción.
Se ha creado este objeto utilizando un lazy var, ya que no nos interesa instanciarlo en cuanto se muestre nuestro ViewController sino cuando vayamos a realizar la primera predicción.
- Instanciamos el modelo de Machine Learning a utilizar. Cuando incluimos un modelo en nuestro proyecto, Xcode nos genera una clase y su inicializador de forma automática. En este caso, Xcode nos ha generado la clase MobileNet.
- Creamos el objeto request con el modelo cargado previamente. Recibiremos la respuesta de la predicción en el objeto request del closure que pasamos como parámetro.
- Procesamos la predicción realizada para obtener el nombre de los objetos detectados.
- Indicamos que antes de procesar la imagen se haga un crop y un scale de la misma. Con esto forzamos a que la imagen que se va a procesar mantenga el aspect ratio correcto, ya que el framework Vision tiene que preprocesar la imagen antes de enviarla al modelo, puesto que el modelo necesita que las imágenes a procesar tengan un tamaño en concreto (tamaño que viene definido en el propio modelo).
private lazy var classificationRequest: VNCoreMLRequest = {
do {
// 1
let model = try VNCoreMLModel(for: MobileNet().model)
// 2
let request = VNCoreMLRequest(model: model) {
Con esto ya tendríamos toda la lógica necesaria para realizar predicciones con el modelo de Machine Learning. Finalmente, procesamos y mostramos las predicciones:
- Si no se ha detectado nada, mostramos el mensaje conveniente.
- Si se ha detectado algo, mostramos las 3 primeras predicciones (Core ML nos devuelve las predicciones ordenadas según su probabilidad de acierto). Además, mostramos su probabilidad de acierto. Esta probabilidad indica qué tan parecido es un objeto a lo que nuestro modelo cree que es.
private func processClassification(for request: VNRequest) -> String {
// 1
guard let results = request.results,
let classifications = results as? [VNClassificationObservation],
!classifications.isEmpty else {
return "Nothing detected"
}
// 2
// return the best 3 results
return classifications
.prefix(3)
.map { "[(Int($0.confidence * 100))%] ($0.identifier)" }
.joined(separator: "n")
}
A continuación mostramos algunos objetos detectados por el modelo:


Puedes descargar aquí el código completo de este proyecto de ejemplo.
Novedades en iOS 14
Se han introducido algunas novedades interesantes en Core ML. A destacar:
- Integración con CloudKit. Podemos almacenar nuestros modelos en CloudKit, lo que nos permitiría actualizar nuestros modelos sin necesidad de publicar una nueva versión de la app.
- Nuevos tipos de modelos. Se incluyen modelos para detectar acciones (por ejemplo, podríamos ser capaces de detectar qué deporte está practicando una persona), y modelos para transferencia de estilos.
- Securización. Posibilidad de encriptar nuestros modelos.
Conclusiones y futuro de Machine Learning
Como hemos visto, añadir Machine Learning a nuestra aplicación es sumamente fácil. Core ML nos proporciona un API sencilla e intuitiva que nos permite centrarnos en el uso de modelos de Machine Learning. Para la implementación del ejemplo visto anteriormente hemos utilizado un modelo open source, pero como indicamos al principio también tenemos la posibilidad de crear nuestros propios modelos utilizando Create ML.
Con iOS 14 y la introducción de modelos para detectar acciones se abre un nuevo abanico de posibilidades, como por ejemplo:
- Implementar un intérprete del lenguaje de signos para personas sordas. Machine Learning podría detectar qué signos se corresponden con qué conceptos, permitiendo realizar una transcripción en tiempo real de lo que está comunicando esa persona.
- Cámaras de seguridad para detección de acciones violentas entre personas, animales, mobiliario urbano, etc., pudiendo avisar a las autoridades pertinentes de forma automática.
- Perfeccionamiento de técnica para deportistas de élite. Machine Learning podría detectar si cierto movimiento o técnica se está realizando de forma adecuada: golpeo de balón en fútbol, saque en tenis, técnica de un arte marcial, etc.
Cabe destacar uno de los retos a los que se enfrenta Machine Learning: la privacidad. Para solventar parte de este tema, se está tendiendo al desarrollo de procesadores dedicados exclusivamente al cálculo y procesamiento de algoritmos neuronales, que se incluyen como parte de la CPU de los dispositivos móviles (algo similar a las GPU que se encargan del procesamiento de gráficos). Gracias a esto, la ejecución de los algoritmos de Machine Learning se realiza en el propio dispositivo con el fin de evitar el compartir información privada con servidores externos.
Este avance se puede ver claramente en los chips Bionic de Apple, que incluyen un co-procesador dedicado para tareas de Machine Learning. De hecho, Core ML se ejecuta siempre sobre modelos de Machine Learning almacenados localmente en el dispositivo, esto es, no se requiere ningún tipo de conexión a Internet ni comunicación con el exterior para ser ejecutados.
A lo largo de los próximos años viviremos un auge de los sistemas autónomos. Muchas de las tareas que todavía gestionan las personas se delegarán completamente en las máquinas, que ya no solo realizarán trabajos monótonos y repetitivos, sino que también serán capaces de tomar decisiones por nosotros de forma más efectiva.

iOS Team
ALTEN





